Dynamo DB - When to use it?
Why DynamoDB over relational databases?
The first question that you should ask yourself before deciding to go with DynamoDB - why should you choose it over relational databases?
Like everything in the software there’s no one tool that fits all solutions, so you must evaluate each tool before deciding to build your application. I’ll try to provide a breif overview on the areas where DynamoDB excels and where you might want to use relational databases instead.
The single biggest advantage that DynamoDB offers is consistent performance. Irrespective of the size of your dataset, DynamoDB will guarantee single-digit millisecond response everytime! This is a huge win compared to relational databases where query time grows with dataset size.
Some other advantages:
-
Fully managed by AWS. No need to self-host and manage the clusters.
-
No downtime for maintaining the database. This is unlike other relational databases like PostgresSQL where you would have to do periodic updates for security patches or using newer features.
How does DynamoDB guarantee < 10ms response time?
To understand how dynamodb guarantees single digit millisecond response time, we need to first understand a little bit about DynamoDB architecture and the limits imposed by it.
Architecture
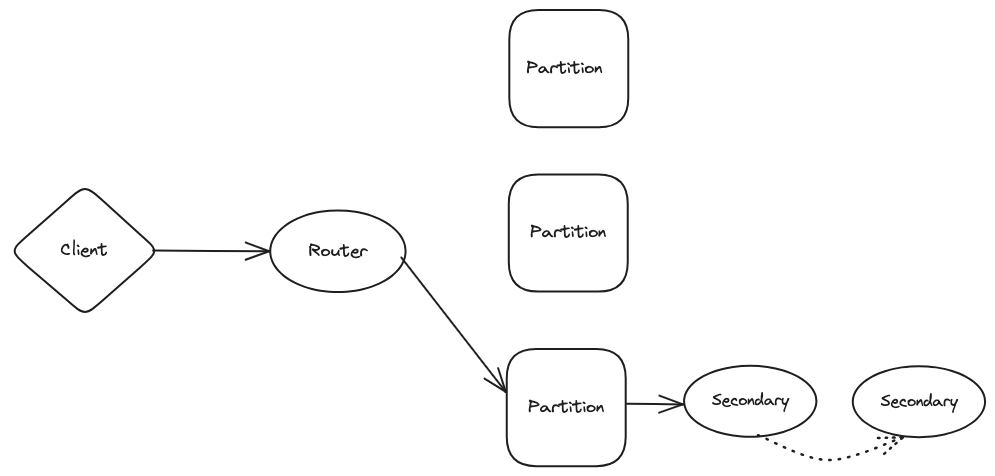
There are 3 main parts to here:
- Router: The router is responsible for getting the request from the client and determining which partition the request should be routed to based on the partition key provided in the request.
- Partition: Every table in DynamoDB has a partition key which decides in which physical partition (server) the data should be stored in. If a sort key is configured for the table then each partition key stores a B-tree with sort key as the value.
- Secondary: Every physical partition (server) has 2 secondary nodes which can be read from to distribute the reads.
During Reads
Request reaches the router and it determines based on the partition key (and optional sort key) to which physical server the request should be routed to. The router uses an internal hash function to determine this. Once the partition is found, data can be read from the primary or the secondary nodes.
During Writes
Pretty much the same as reads, except that once the partition is found the data is written to the primary followed by one of the secondary nodes if either of them fails then the write operation fails. The data is also written asynchronously to the second secondary node.
Limits
Critical limits in DynamoDB:
- Each item in the table is restricted to 400kb.
- A single physical partition (server) contains only 10GB of data.
- In a sigle read operation only 1Mb of data is returned.
Now, lets look at the time complexity of reads and writes -
For both reading and writing an item in the table where both partition key and sort key is provided - it takes O(1) to find the parition and O(logN) to find the sort key. Here N is restricted to (10GB / 400kb) ~2.5mil rows of data, this is how dynamo DB guarantees single digit millisecond response time.